Данные
🔗 Оригинальная страница — Источник данного материала
О�писание
Данный экшен предназначен для получения данных со страницы.
Как добавить действие в проект?
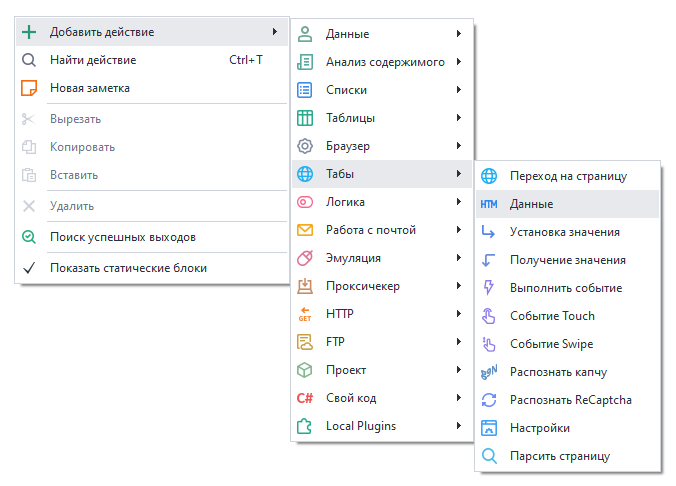
Через контекстное меню: Добавить действие → Табы → Данные
Для чего это используется?
- Найти и сохранить нужную информацию со страницы
- Проверить, есть ли какие-то значения на странице
- Спарсить текст со страницы
- Взять URL страницы
Принцип работы
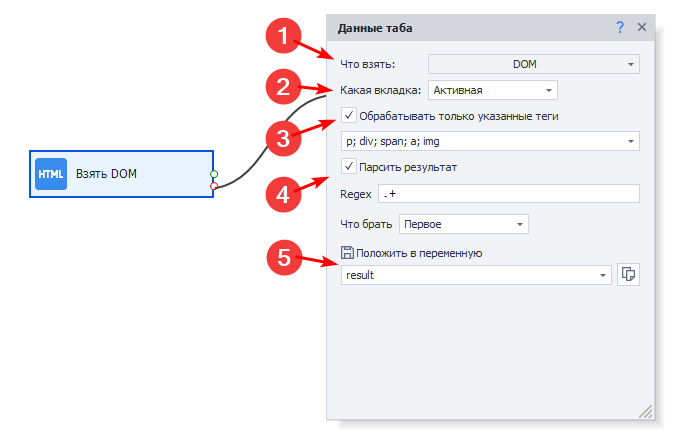
Что взять
Выбираем тип данных, которые хотим получить:
- DOM — объектная модель документа;
- Source — исходный код страницы;
- Text — видимый текст страницы;
- URL — адрес ссылки из адресной строки.
Какая вкладка
Определяем вкладку, с которой берём данные:
- Активная — текущая активная вкладка;
- Первая — если вкладок несколько, то взять первую по счёту;
- По имени — выбрать вкладку по её имени;
- По номеру — выбрать вкладку по номеру (если их н�есколько).
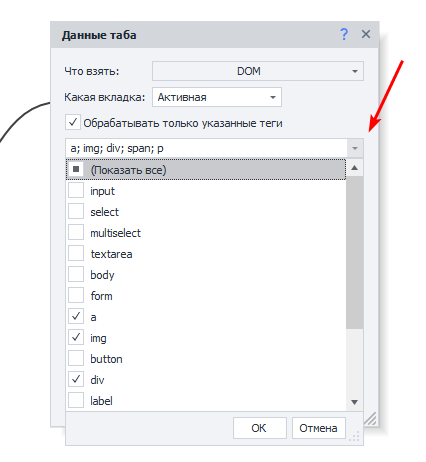
Обрабатывать только указанные теги
Если необходимо обрабатывать один конкретный или несколько определённых HTML-тегов, то активируем чекбокс и выбираем нужные варианты.
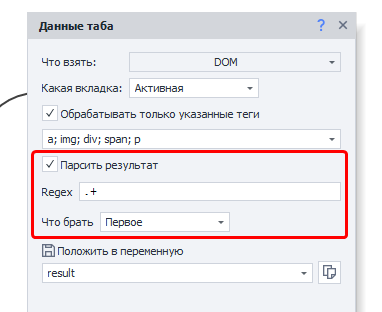
Парсить результат
При необходимости результат можно распарсить, указав регулярное выражение (Regex), нужные совпадения и место сохранения — переменную или таблицу.
Подобрать подходящее регулярное выражение можно с помощью Тестера регулярных выражений.
Это более удобный инструмент для получения данных со страницы.
Разница между «Source» и «DOM»
Source — исходный код страницы, который получен с сервера.
DOM — это дерево объектов, которые браузер создает в памяти компьютера на основании исходного кода, полученного им от сервера.
Если сильно упростить, то браузер работает следующим образом:
- Вы вводите в адресную строку URL и нажимаете
Enter. - Браузер отправляет запрос на сервер.
- Сервер возвращает ответ в виде исходного HTML-кода страницы (Source).
- На основе исходного кода браузер строит DOM (Data Object Model — объектная модель документа). А также:
- обрабатывает ошибки (добавляет теги html, body, head и другие, если они не были написаны).
- закрывает незакрытые теги.
- добавляет тег
<tbody>к таблицам (<table>), если его не было. А в HTML этот тег можно не использовать. Учитывайте это при построении XPath и Регулярных выражений - обрабатывает скрипты, которые могут добавлять новые элементы во время и после полной загрузки страницы.
- По итогу браузер на основе DOM отрисовывает и показывает содержимое веб-страницы.
DOM может содержать элементы, отсутствующие в исходном коде (Source), поскольку он формируется с учётом контента, динамически добавляемого через JavaScript.
Два инструмента для просмотра «Source» и «DOM»
Просмотр исходного кода
Инструменты web-разработчика (только для движка Chrome)
Пример использования
Хотим получить все ссылки со страницы.
Что взять: «Source» или «DOM» → затем парсить результат → указываем регулярное выражение Regex: (?<=href=")http.*?(?=")
Берём все значения, а результат отправляем в список.
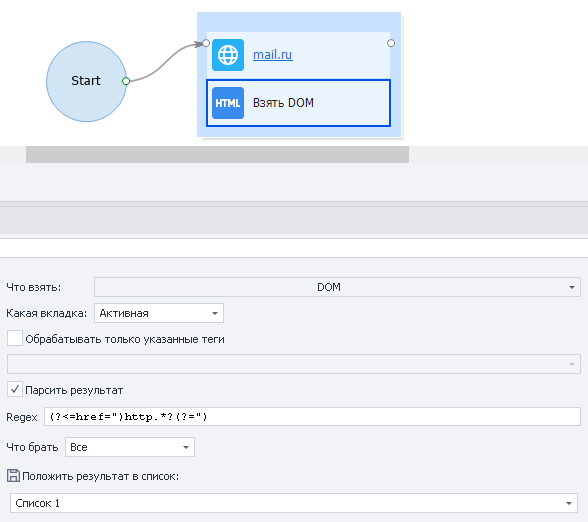
В итоге, как и хотели, получим все ссылки, имеющиеся на выбраной странице.