XPath
🔗 Оригинальная страница — Источник данного материала
Описание
Это язык запросов, который позволяет находить нужные элементы и атрибуты в XML и (X)HTML документах. Проще говоря, с его помощью можно указать путь к нужному элементу в структуре документа и быстро получить к нему доступ.
XPath является стандартом консорциума W3C и широко используется при работе с DOM-структурой страниц и XML-файлов.
Как используется XPath в ZennoPoster?
- Для парсинга данных с сайтов;
- Для поиска и взаимодействия с элементами на веб-странице:
- В конструкторе действий.
С помощью XPath можно реализовать более универсальный и устойчивый к изменениям вёрстки сайта алгоритм поиска данных в сравнении с регулярными выражениями. Данный язык запросов позволяет значительно упростить логику парсеров и тем самым ускорить их разработку.
Тестирование запросов
- В ZennoPoster встроен Тестер X\Json Path с помощью которого можно протестировать составленное выражение.
- Так же составить и протестировать XPath можно в окне Инcтрументов web-разработчика: откройте окно DevTools, нажмите
CTRL+Fдля вызова строки поиска и введите в неё XPath выражение.
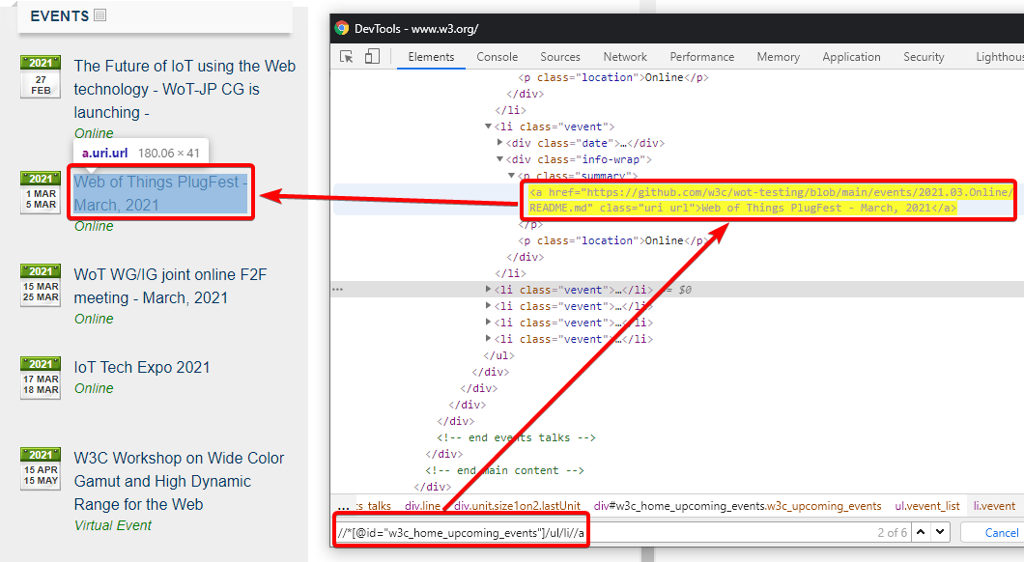
Например, чтобы получить названия мероприятий на сайте http://w3.org, мы можем использовать следующее выражение:
//*[@id="w3c_home_upcoming_events"]/ul/li//a
Базовый синтаксис
Пути
| Выражение | Описание |
|---|---|
. | текущий контекст |
.// | рекурсивный спуск (на ноль или более уровней от текущего контекста) |
/html/body | абсолютный путь |
a | относительный путь |
//* | все в текущем контексте |
li//a | ссылки, являющиеся «внуками» для li |
//a | //button | ссылки и кнопки (объединение двух множеств узлов) |
Отношения
| Выражение | Описание |
|---|---|
a/i/parent::p | непосредственный родитель <p> |
p/ancestor::\ | все родители |
p/following-sibling::\ | все следующие братья |
p/preceding-sibling::\ | все предыдущие братья |
p/following::\ | все следующие элементы кроме потомков |
p/preceding::\ | все предыдущие элементы кроме предков |
p/descendant-or-self::\ | контекстный узел и все его потомки |
p/ancestor-or-self::\ | контекстный узел и все его предки |
Получение узлов
| Выражение | Описание |
|---|---|
/div/text() | получить текстовые узлы |
/div/text()[1] | получить первый текстовый узел |
Позиция элемента
| Выражение | Описание |
|---|---|
a[1] | первый э�лемент |
a[last()] | последний элемент |
a[2] | вторая ссылка |
a[position() <= 3] | первые 3 ссылки |
ul[li[1]=”OK”] | список (UL), первый элемент которого содержит значение OK |
tr[position() mod 2 = 1] | не четные элементы |
tr[position() mod 2 = 0] | четные элементы |
p/text()[2] | второй текстовый узел |
Атрибуты и фильтры
[]— указывает на фильтрацию элементов
| Выражение | Описание |
|---|---|
input[@type=”text”] | тег <input> у которого атрибут type равен text |
input[@class='OK'] | тег <input> у которого атрибут class равен OK |
p[not(@\)] | параграфы без атрибутов |
[@style] | все элементы с атрибутом style |
a[. = “OK”] | ссылки со значением OK |
a/@id | идентификаторы ссылок |
a/@\ | все атрибуты ссылок |
| ссылки, которые содержат атрибуты id и rel |
a[i or b] | ссылки содержат элемент <i> или <b> |
Функции
Базовые функции Xpath - http://www.w3.org/TR/xpath/#corelib
| Функция | Описание | Пример |
|---|---|---|
name() | Возвращает имя элемента | [name()='a'] |
string(val) | Получить значение атрибута | string(a[1]/@id) |
substring(val, from, to) | Вырезать часть строки | substring(@id, 1, 6) |
substring-before(val, to) | Вернуть часть строки val перед строкой to | substring-before('12-May-1998', '-') = '12' |
substring-after(val, from) | Вернуть часть строки val после строки to | substring-after('12-May-1998', '-') = 'May-1998' |
string-length() | Возвращает число символов в строке | [string-length(text()) > 5] |
count() | Возвращает количество элементов | |
concat() | Принимает на вход две или более строки и возвращает конкатенацию (строковое сложение) своих аргументов. | |
normalize-space() | Аналог Trim | [normalize-space(text())='SEARCH'] |
starts-with() | Начинается с | [starts-with(text(), 'SEARCH')] |
contains() | Содерж�ит | [contains(name(), 'SEARCH')] |
translate(val, from, to) | Производит замену символов первого своего строкового аргумента, которые присутствуют во втором аргументе на соответствующие символы третьего аргумента. | translate(«bar»,«abc»,«ABC») |
Группирование
| Выражение | Описание |
|---|---|
(table/tbody/tr)[last()] | последняя строка <tr> из всех таблиц |
(//h1|//h2)[contains(text(), 'Text')] | заголовок первого или второго уровня, который содержит Text |
a[//tr/@data-id=@data-id] | все ссылки у которых атрибут data-id совпадает с этим же атрибутом у строки таблицы |