Шаг 5. Приступаем к обучению
Описание.
**Когда все предыдущие этапы завершены, можно переходить к обучению собственного модуля распознавания капч"".
Общая концепция обучения.
На начальном этапе рекомендуется использовать упрощённое ядро и провести быстрое тестовое обучение:
1. Возьмите примерно треть доступных символов для теста;
2. Запустите обучение на несколько десятков итераций;
3. Оцените результат и при необходимости скорректируйте параметры;
4. После этого можно обучать модуль с более мощным ядром и улучшенными настройками для достижения максимальной точности.
Такой подход позволяет быстрее понять, насколько корректны ваши параметры и фильтры, не тратя время на длительное обучение.
Основные типы ошибок.
- Неправильное распозна�вание.
Символ действительно присутствует, но определяется неверно. Например, вместоамодуль считает, что этос. - Пропуск символа.
Символ на изображении есть, но модуль его совсем не видит. То есть мы показываема, а система считает, что в этом месте ничего нет. - Ложное срабатывание.
Модуль находит символ там, где его на самом деле нет, например, между двумя буквами.
Понимание этих трёх типов ошибок поможет точнее анализировать результаты обучения и грамотно корректировать настройки для следующей итерации.
Подготовка к обучению.
Настройки ядра.

Мощность ядра определяет баланс между качеством распознавания и скоростью работы модуля:
- Выше мощность — модуль точнее распознаёт символы, но при этом снижается скорость и растёт нагрузка на процессор.
- Ниже мощность — модуль работает быстрее, но чаще допускает ошибки.
Как подобрать оптимальную мощность?
Не стоит начинать с максимальных значений. Попробуйте самое простое ядро — возможно, его точности будет вполне достаточно для ваших задач. Если нет, то постепенно повышайте мощность, наблюдая за результатами.
Рядом с параметром отображается оценка сложности ядра — это число показывает, сколько процессорного времени требуется на обработку одной точки. Это не абсолютная единица измерения, а лишь ориентир для сравнения: если одно ядро имеет сложность в два раза выше, то и работать оно будет примерно в два раза дольше при прочих равных условиях.
Что влияет на сложность?
На итоговую сложность ядра влияют два параметра:
- Мощность ядра;
- Размер окна распознавания символа.
Регулируя эти значения, вы сможете подобрать оптимальное соотношение скорости и точности, чтобы модуль работал эффективно и стабильно.
Параметры обучения.

Скорость.
Чем медленнее проходит обучение, тем качественнее будет результат.
Однако не стоит сразу запускать длительное обучение — начните с быстрого режима. Так вы сможете выявить возможные ошибки и исправить их, прежде чем тратить время на полноценное обучение.
Стартовый параметр.
Этот параметр определяет начальную скорость обучения.
Менять его следует только при появлении ошибок, связанных с процессом обучения (о них расскажем далее). В обычных случаях оставляйте значение по умолчанию.
Разброс центров символов.
Во время обучения каждый собранный символ представляется ядру в точке, которую вы указали как центр символа.
Можно немного увеличить разброс этих точек — иногда это помогает повысить устойчивость распознавания. Но в некоторых случаях, наоборот, может ухудшить результат.
Интенсивность обучения на ложных данных.
Если при обучении или распознавании часто возникают ложные срабатывания, то попробуйте увеличить этот параметр. Это помогает системе эффективнее различать реальные символы и фон.
10.Доля обучающих символов.
Не все собранные символы участвуют в обучении — часть из них используется для тестирования ядра во время обучения (по первому графику).
Этот тест очень важен: он показывает, как идёт процесс и нужно ли что-то корректировать. Для теста должно быть не меньше 30–50 символов. Но и слишком много на это выделять не стоит, �оставьте побольше для обучения.
Рекомендуем такую стратегию:
1. Первое обучение — с большим количеством тестовых символов, чтобы отладить параметры.
2. Повторное (финальное) обучение — с использованием почти всех собранных символов, оставив минимум для теста, чтобы достичь максимального качества.
Параметры распознавания.

Порог распознавания.
Когда ядро анализирует участок капчи, оно выдаёт для каждого символа значение от 0 до 1:
0— символа точно нет,1— ядро уверено, что символ находится именно здесь.
Чтобы получить чёткий ответ (“да” или “нет”), используется порог распознавания.
Если значение выше порога — считается, что символ найден, если ниже — игнорируется.
Позже, в разделе об ошибках обучения, вы узнаете, как менять этот параметр, чтобы корректировать поведение модуля.
Минимальное расстояние между символами.
Этот параметр не позволяет модулю искать новые символы слишком близко к уже найденным. Так удаётся избежать множества ошибочных срабатываний.
Чтобы определить подходящее значение:
1. Откройте одну из капч в Paint (или любом другом редакторе).
2. Увеличьте масштаб так, как это делает ваш фильтр.
3. Измерьте минимальное расстояние в пикселях между соседними символами.
Если ошибётесь — ничего страшного: в процессе тестирования модуля легко скорректировать этот параметр без переобучения.
Количество капч для тестирования.
Во время обучения система регулярно проводит тестовое распознавание капч, чтобы определить текущий процент точности.
- Много капч → тест точнее, но занимает больше времени.
- Мало капч → тест проходит быстро, но результат менее надёжен.
После нескольких циклов обучения вы сможете подобрать оптимальный баланс.
Частота тестирования.
Чтобы не тратить ресурсы зря, тестирование проводится не после каждого цикла обучения, а через определённые интервалы.
Этот параметр задаёт, через сколько циклов запускать проверку.
Быстрое распознавание.
Для очень сложных капч (с плотными строками, сильными искажениями и множеством помех) обучение и распознавание могут занимать много времени.
Включение этого параметра активирует оптимизации, ускоряющие процесс распознавания примерно в 5–10 раз. Однако это может немного снизить точность.
Вы можете включить параметр перед обучением, чтобы ускорить тесты. Или применить его позже, уже при проверке готового модуля. Если процент распознавания после этого изменится, попробуйте скорректировать настройки центров масс.
Без него вы получите максимально точную оценку потенциала своего модуля.
Процесс обучения.
Графики с результатами.
После установки всех параметров наконец можно запустить само обучение. В процессе работы вам станет доступна статистика, отображающаяся в виде трёх графиков.
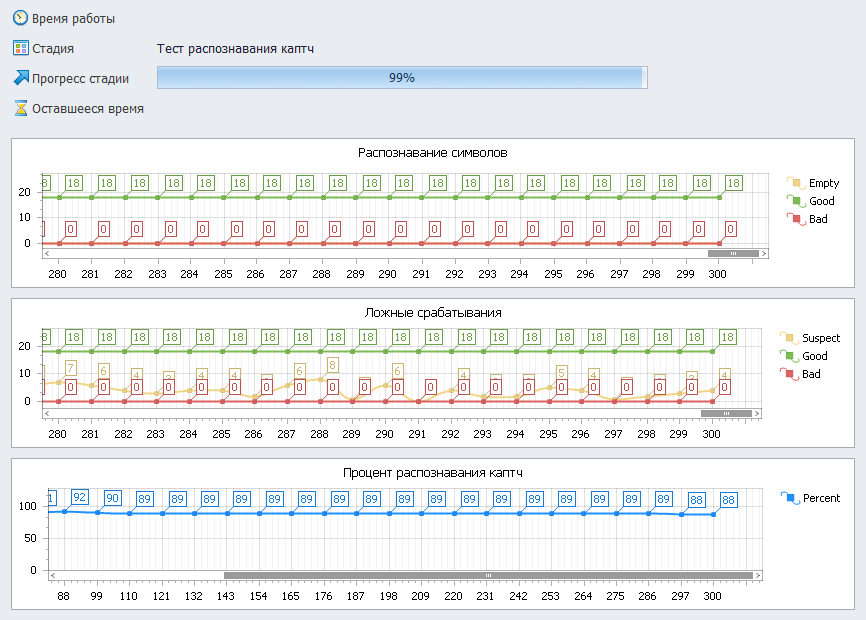
Распознавание символов.
Первый график информирует о том, как модуль справляется с вашими собранными символами:
- Зелёная линия — количество правильно распознанных символов.
- Жёлтая линия — количество случаев, когда ядро не нашло символ вовсе (вторая ошибка распознавания).
- Красная линия — количество неверно распознанных символов (первая ошибка распознавания).
Проверка на ложные срабатывания.
На этом графике видно, как модуль реаг�ирует на те места, где символов быть не должно:
- Зелёная линия — количество корректных ответов (модуль ничего не нашёл — и это правильно).
- Жёлтая линия — количество случаев подозрительной активности ядра.
- Красная линия — количество ошибок ложного срабатывания (третья ошибка распознавания).
Общий процент распознавания.
Третий график показывает предварительный процент точности работы модуля — это наглядная оценка, насколько хорошо обученная модель справляется с распознаванием капч в текущем состоянии.
Остановка обучения.
Процесс обучения можно остановить в любой момент, если вы видите, что результаты больше не улучшаются.

После остановки (вручную или автоматически — по достижении 300 циклов) необходимо выбрать, какое ядро будет использоваться в вашем модуле.
Варианты для выбора ядра:
- С лучшим процентом распознавания.
В этом случае будет выбрано то ядро, на котором система показала максимальную точность распознавания, даже если оно не было последним в процессе обучения. - Последнее ядро.
Подходит, если в тестировании использовалось мало капч (менее 50), и разница между последним ядром и лучшим по проценту распознавания незначительна. Тогда логичнее взять последний вариант, как наиболее актуальный. - Ядро от предыдущего обучения.
Если с прошлыми настройками модуль показывал лучший результат, можно оставить предыдущее ядро, не заменяя его новым.
Как выглядят правильные результаты обучения.
При удачно настроенном и стабильном обучении графики должны показывать следующие тенденции:
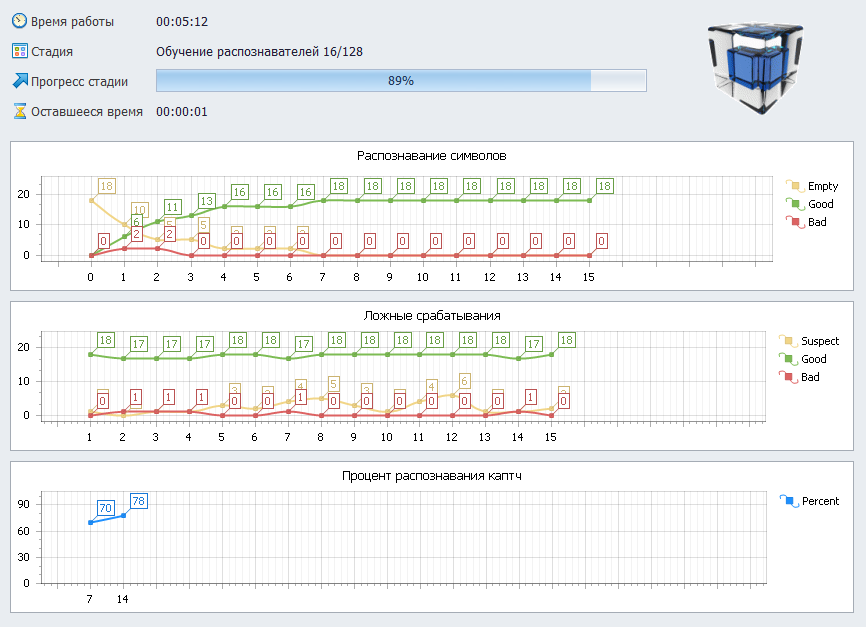
График распознавания символов:
- Зелёная линия — уверенно растёт к максимуму (всё больше символов распознаётся правильно).
- Жёлтая и красная линии — постепенно снижаются к нулю (уменьшается количество пропусков и ошибок распознавания).
График ложных срабатываний.
- Зелёная линия — всегда наверху, отражая большое количество правильных пустых ответов (где символов действительно нет).
- Жёлтая линия — немного выше красной (примерно в 5–10 раз), но ниже зелёной.
- Красная линия — близка к нулю (минимум ложных срабатываний).
Последний график.
Процент распознавания должен постепенно расти: в начале — быстро, затем — медленнее, по мере приближения к стабильному уровню точности.
Имейте в виду, что у вас графики могут выглядеть немного иначе:
- начальный процент может быть ниже;
- рост зелёной линии — медленнее;
- спад жёлтой и красной — постепеннее.
Это зависит от настроек обучения, качества фильтров и сложности капчи.
Исправление ошибок.
Если вы долго не можете добиться нормальных результатов, а приведённые ниже советы не помогают — не тратьте время впустую.
Просто напишите на форуме в разделе программы — вам подскажут, что именно не так.
Графики долго не растут после начала обучения.
Зелёная и красная линии стоят на месте даже спустя десятки циклов. Это значит, что ядро не обучается.
Попробуйте увеличить стартовый параметр обучения примерно в 10 раз и перезапустите процесс. Повторяйте, пока линии не начнут подниматься.
Красная линия выше зелёной на первом графике.
Ошибок больше, чем правильных ответов.
Возможные причины:
- Слишком большой стартовый параметр обучения.
Уменьшайте его в 10 раз и пробуйте заново, пока ситуация не улучшится. Если после уменьшения появляется предыдущая ошибка — дело не только в параметре. - Мало обучающих символов или неверно настроены фильтры.
Проверьте фильтрацию. - Ошибки в именах символов.
Возможно, при сборе вы присвоили им неправильные буквы. Проверьте коллекцию в разделе Фильтры (нажмите «Показывать текст», чтобы сравнить изображение и подпись под ним).
Красная линия остаётся высоко (много ошибок 1-го типа).
Символы распознаются неправильно.
Причин много:
- недостаточно собранных символов;
- слишком сложная капча;
- сеть слишком простая;
- обучение идёт слишком быстро;
- большой разброс центров масс;
- много разных символов в капче.
До начала обучения красная линия (Bad results) уже высокая.
Не пугайтесь — это не ошибка.
Просто установлен низкий порог распознавания (0.5 или ниже). После первого цикла обучения ситуация должна нормализоваться.
После 100+ циклов жёлтая линия не падает к нулю.
Ядро не распознаёт многие символы — ошибка 2-го типа.
Возможные причины:
- Слишком высокий порог обучения — оптимальны значения 0.5-0.6;
- Слишком маленький стартовый параметр обучения — увеличьте его в 3–5 раз;
- Мало обучающих символов, причём они сильно искажены;
- Сеть слишком сложная;
- Обучение идёт слишком быстро.
На втором графике сильно выросла красная линия.
Много ложных срабатываний (ошибка 3-го типа).
Увеличьте интенсивность обучения на ложных данных — ядро станет осторожнее при распознавании.
Третий график показывает 0% распознавания, хотя остальные графики нормальные.
Обучение формально идёт хорошо, но капча не распознаётся. Возможно, проблема в логике тестирования.
Доучите модуль, пока графики 1 и 2 стабилизируются на одинаковых уровнях. Затем остановите обучение, перейдите во вкладку «Тестирование модуля» и запустите тест. Посмотрите, какие конкретно ошибки возникают, и загляните в раздел справки по тестированию — там указано, как их устранить.
Если зелёная линия растёт, а красная и жёлтая постепенно падают, значит вы на верном пути.
Параметры тестирования модуля.
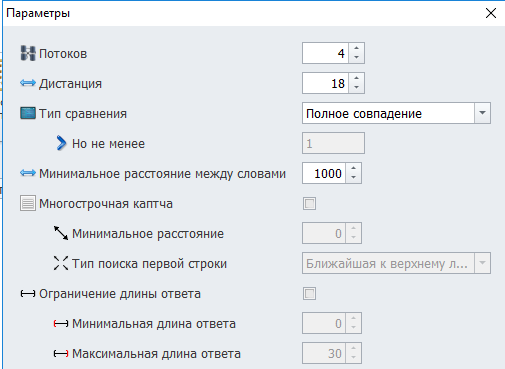
Потоков.
Количество параллельных потоков, в которых выполняется тестирование.
Чем больше потоков — тем быстрее проходит тест, но тем выше нагрузка на процессор.
Дистанция.
Минимальное расстояние между символами внутри капчи.
Помогает избежать ситуаций, когда модуль принимает слипшиеся символы за один или путает границы между ними.
Тип сравнения.
Определяет, как оценивается успешность теста.
Если при сравнении обнаруживается несколько совпадающих слов, тест считается успешным.
Минимальное расстояние между словами.
Минимальное допустимое расстояние между словами на капче.
Используется для разделения фраз, если капча содержит несколько слов подряд.
Многострочная каптча.
Этот параметр нужен для работы с многострочными капчами, например, SolveMedia.
Включите его, если текст на капче расположен в две или более строк — тогда изображение будет обработано корректно.
Минимальное расстояние между строками.
Определяет расстояние между строками текста.
Измеряется как дистанция между левым нижним углом символов верхней строки и правым верхним углом символов нижней строки.
Ограничение длины ответа.
Позволяет задать допустимую длину распознанного текста.
Ответы, выходящие за пределы этого диапазона, будут отброшены.
Этот параметр используется только в тестировании модулей.